The Go Blog
A GIF decoder: an exercise in Go interfaces
Introduction
At the Google I/O conference in San Francisco on May 10, 2011, we announced that the Go language is now available on Google App Engine. Go is the first language to be made available on App Engine that compiles directly to machine code, which makes it a good choice for CPU-intensive tasks such as image manipulation.
In that vein, we demonstrated a program called Moustachio that makes it easy to improve a picture such as this one:

by adding a moustache and sharing the result:

All the graphical processing, including rendering the antialiased moustache, is done by a Go program running on App Engine. (The source is available at the appengine-go project.)
Although most images on the web—at least those likely to be moustachioed—are JPEGs, there are countless other formats floating around, and it seemed reasonable for Moustachio to accept uploaded images in a few of them. JPEG and PNG decoders already existed in the Go image library, but the venerable GIF format was not represented, so we decided to write a GIF decoder in time for the announcement. That decoder contains a few pieces that demonstrate how Go’s interfaces make some problems easier to solve. The rest of this blog post describes a couple of instances.
The GIF format
First, a quick tour of the GIF format. A GIF image file is paletted, that is, each pixel value is an index into a fixed color map that is included in the file. The GIF format dates from a time when there were usually no more than 8 bits per pixel on the display, and a color map was used to convert the limited set of values into the RGB (red, green, blue) triples needed to light the screen. (This is in contrast to a JPEG, for example, which has no color map because the encoding represents the distinct color signals separately.)
A GIF image can contain anywhere from 1 to 8 bits per pixel, inclusive, but 8 bits per pixel is the most common.
Simplifying somewhat, a GIF file contains a header defining the pixel depth and image dimensions, a color map (256 RGB triples for an 8-bit image), and then the pixel data. The pixel data is stored as a one-dimensional bit stream, compressed using the LZW algorithm, which is quite effective for computer-generated graphics although not so good for photographic imagery. The compressed data is then broken into length-delimited blocks with a one-byte count (0-255) followed by that many bytes:
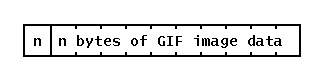
Deblocking the pixel data
To decode GIF pixel data in Go, we can use the LZW decompressor from the
compress/lzw package.
It has a NewReader function that returns an object that,
as the documentation says,
“satisfies reads by decompressing the data read from r”:
func NewReader(r io.Reader, order Order, litWidth int) io.ReadCloser
Here order defines the bit-packing order and litWidth is the word size in bits,
which for a GIF file corresponds to the pixel depth, typically 8.
But we can’t just give NewReader the input file as its first argument
because the decompressor needs a stream of bytes but the GIF data is a stream
of blocks that must be unpacked.
To address this problem, we can wrap the input io.Reader with some code to deblock it,
and make that code again implement Reader.
In other words, we put the deblocking code into the Read method of a new type,
which we call blockReader.
Here’s the data structure for a blockReader.
type blockReader struct {
r reader // Input source; implements io.Reader and io.ByteReader.
slice []byte // Buffer of unread data.
tmp [256]byte // Storage for slice.
}
The reader, r, will be the source of the image data,
perhaps a file or HTTP connection.
The slice and tmp fields will be used to manage the deblocking.
Here’s the Read method in its entirety.
It’s a nice example of the use of slices and arrays in Go.
1 func (b *blockReader) Read(p []byte) (int, os.Error) {
2 if len(p) == 0 {
3 return 0, nil
4 }
5 if len(b.slice) == 0 {
6 blockLen, err := b.r.ReadByte()
7 if err != nil {
8 return 0, err
9 }
10 if blockLen == 0 {
11 return 0, os.EOF
12 }
13 b.slice = b.tmp[0:blockLen]
14 if _, err = io.ReadFull(b.r, b.slice); err != nil {
15 return 0, err
16 }
17 }
18 n := copy(p, b.slice)
19 b.slice = b.slice[n:]
20 return n, nil
21 }
Lines 2-4 are just a sanity check: if there’s no place to put data, return zero. That should never happen, but it’s good to be safe.
Line 5 asks if there’s data left over from a previous call by checking the
length of b.slice.
If there isn’t, the slice will have length zero and we need to read the
next block from r.
A GIF block starts with a byte count, read on line 6.
If the count is zero, GIF defines this to be a terminating block,
so we return EOF on line 11.
Now we know we should read blockLen bytes,
so we point b.slice to the first blockLen bytes of b.tmp and then
use the helper function io.ReadFull to read that many bytes.
That function will return an error if it can’t read exactly that many bytes,
which should never happen.
Otherwise we have blockLen bytes ready to read.
Lines 18-19 copy the data from b.slice to the caller’s buffer.
We are implementing Read, not ReadFull,
so we are allowed to return fewer than the requested number of bytes.
That makes it easy: we just copy the data from b.slice to the caller’s buffer (p),
and the return value from copy is the number of bytes transferred.
Then we reslice b.slice to drop the first n bytes,
ready for the next call.
It’s a nice technique in Go programming to couple a slice (b.slice) to an array (b.tmp).
In this case, it means blockReader type’s Read method never does any allocations.
It also means we don’t need to keep a count around (it’s implicit in the slice length),
and the built-in copy function guarantees we never copy more than we should.
(For more about slices, see this post from the Go Blog.)
Given the blockReader type, we can unblock the image data stream just
by wrapping the input reader,
say a file, like this:
deblockingReader := &blockReader{r: imageFile}
This wrapping turns a block-delimited GIF image stream into a simple stream
of bytes accessible by calls to the Read method of the blockReader.
Connecting the pieces
With blockReader implemented and the LZW compressor available from the library,
we have all the pieces we need to decode the image data stream.
We stitch them together with this thunderclap,
straight from the code:
lzwr := lzw.NewReader(&blockReader{r: d.r}, lzw.LSB, int(litWidth))
if _, err = io.ReadFull(lzwr, m.Pix); err != nil {
break
}
That’s it.
The first line creates a blockReader and passes it to lzw.NewReader
to create a decompressor.
Here d.r is the io.Reader holding the image data,
lzw.LSB defines the byte order in the LZW decompressor,
and litWidth is the pixel depth.
Given the decompressor, the second line calls io.ReadFull to decompress
the data and store it in the image, m.Pix.
When ReadFull returns, the image data is decompressed and stored in the image,
m, ready to be displayed.
This code worked first time. Really.
We could avoid the temporary variable lzwr by placing the NewReader
call into the argument list for ReadFull,
just as we built the blockReader inside the call to NewReader,
but that might be packing too much into a single line of code.
Conclusion
Go’s interfaces make it easy to construct software by assembling piece parts
like this to restructure data.
In this example, we implemented GIF decoding by chaining together a deblocker
and a decompressor using the io.Reader interface,
analogous to a type-safe Unix pipeline.
Also, we wrote the deblocker as an (implicit) implementation of a Reader interface,
which then required no extra declaration or boilerplate to fit it into the
processing pipeline.
It’s hard to implement this decoder so compactly yet cleanly and safely in most languages,
but the interface mechanism plus a few conventions make it almost natural in Go.
That deserves another picture, a GIF this time:

The GIF format is defined at http://www.w3.org/Graphics/GIF/spec-gif89a.txt.
Next article: Spotlight on external Go libraries
Previous article: Go at Google I/O 2011: videos
Blog Index