The Go Blog
Toward Go 2
Introduction
[This is the text of my talk today at Gophercon 2017, asking for the entire Go community’s help as we discuss and plan Go 2.]
On September 25, 2007, after Rob Pike, Robert Griesemer, and Ken Thompson had been discussing a new programming language for a few days, Rob suggested the name “Go.”

The next year, Ian Lance Taylor and I joined the team, and together the five of us built two compilers and a standard library, leading up to the open-source release on November 10, 2009.
For the next two years, with the help of the new Go open source community, we experimented with changes large and small, refining Go and leading to the plan for Go 1, proposed on October 5, 2011.

With more help from the Go community, we revised and implemented that plan, eventually releasing Go 1 on March 28, 2012.

The release of Go 1 marked the culmination of nearly five years of creative, frenetic effort that took us from a name and a list of ideas to a stable, production language. It also marked an explicit shift from change and churn to stability.
In the years leading to Go 1, we changed Go and broke everyone’s Go programs nearly every week. We understood that this was keeping Go from use in production settings, where programs could not be rewritten weekly to keep up with language changes. As the blog post announcing Go 1 says, the driving motivation was to provide a stable foundation for creating reliable products, projects, and publications (blogs, tutorials, conference talks, and books), to make users confident that their programs would continue to compile and run without change for years to come.
After Go 1 was released, we knew that we needed to spend time using Go in the production environments it was designed for. We shifted explicitly away from making language changes toward using Go in our own projects and improving the implementation: we ported Go to many new systems, we rewrote nearly every performance-critical piece to make Go run more efficiently, and we added key tools like the race detector.
Now we have five years of experience using Go to build large, production-quality systems. We have developed a sense of what works and what does not. Now it is time to begin the next step in Go’s evolution and growth, to plan the future of Go. I’m here today to ask all of you in the Go community, whether you’re in the audience at GopherCon or watching on video or reading the Go blog later today, to work with us as we plan and implement Go 2.
In the rest of this talk, I’m going to explain our goals for Go 2; our constraints and limitations; the overall process; the importance of writing about our experiences using Go, especially as they relate to problems we might try to solve; the possible kinds of solutions; how we will deliver Go 2; and how all of you can help.
Goals
The goals we have for Go today are the same as in 2007. We want to make programmers more effective at managing two kinds of scale: production scale, especially concurrent systems interacting with many other servers, exemplified today by cloud software; and development scale, especially large codebases worked on by many engineers coordinating only loosely, exemplified today by modern open-source development.
These kinds of scale show up at companies of all sizes. Even a five-person startup may use large cloud-based API services provided by other companies and use more open-source software than software they write themselves. Production scale and development scale are just as relevant at that startup as they are at Google.
Our goal for Go 2 is to fix the most significant ways Go fails to scale.
(For more about these goals, see Rob Pike’s 2012 article “Go at Google: Language Design in the Service of Software Engineering” and my GopherCon 2015 talk “Go, Open Source, Community.”)
Constraints
The goals for Go have not changed since the beginning, but the constraints on Go certainly have. The most important constraint is existing Go usage. We estimate that there are at least half a million Go developers worldwide, which means there are millions of Go source files and at least a billion of lines of Go code. Those programmers and that source code represent Go’s success, but they are also the main constraint on Go 2.
Go 2 must bring along all those developers. We must ask them to
unlearn old habits and learn new ones only when the reward is great.
For example, before Go 1, the method implemented by error types was
named String. In Go 1, we renamed it Error, to distinguish error types
from other types that can format themselves. The other day I was
implementing an error type, and without thinking I named its method
String instead of Error, which of course did not compile. After five
years I still have not completely unlearned the old way. That kind of
clarifying renaming was an important change to make in Go 1 but would
be too disruptive for Go 2 without a very good reason.
Go 2 must also bring along all the existing Go 1 source code. We must not split the Go ecosystem. Mixed programs, in which packages written in Go 2 import packages written in Go 1 and vice versa, must work effortlessly during a transition period of multiple years. We’ll have to figure out exactly how to do that; automated tooling like go fix will certainly play a part.
To minimize disruption, each change will require careful thought, planning, and tooling, which in turn limits the number of changes we can make. Maybe we can do two or three, certainly not more than five.
I’m not counting minor housekeeping changes like maybe allowing identifiers in more spoken languages or adding binary integer literals. Minor changes like these are also important, but they are easier to get right. I’m focusing today on possible major changes, such as additional support for error handling, or introducing immutable or read-only values, or adding some form of generics, or other important topics not yet suggested. We can do only a few of those major changes. We will have to choose carefully.
Process
That raises an important question. What is the process for developing Go?
In the early days of Go, when there were just five of us, we worked in a pair of adjacent shared offices separated by a glass wall. It was easy to pull everyone into one office to discuss some problem and then go back to our desks to implement a solution. When some wrinkle arose during the implementation, it was easy to gather everyone again. Rob and Robert’s office had a small couch and a whiteboard, so typically one of us went in and started writing an example on the board. Usually by the time the example was up, everyone else had reached a good stopping point in their own work and was ready to sit down and discuss it. That informality obviously doesn’t scale to the global Go community of today.
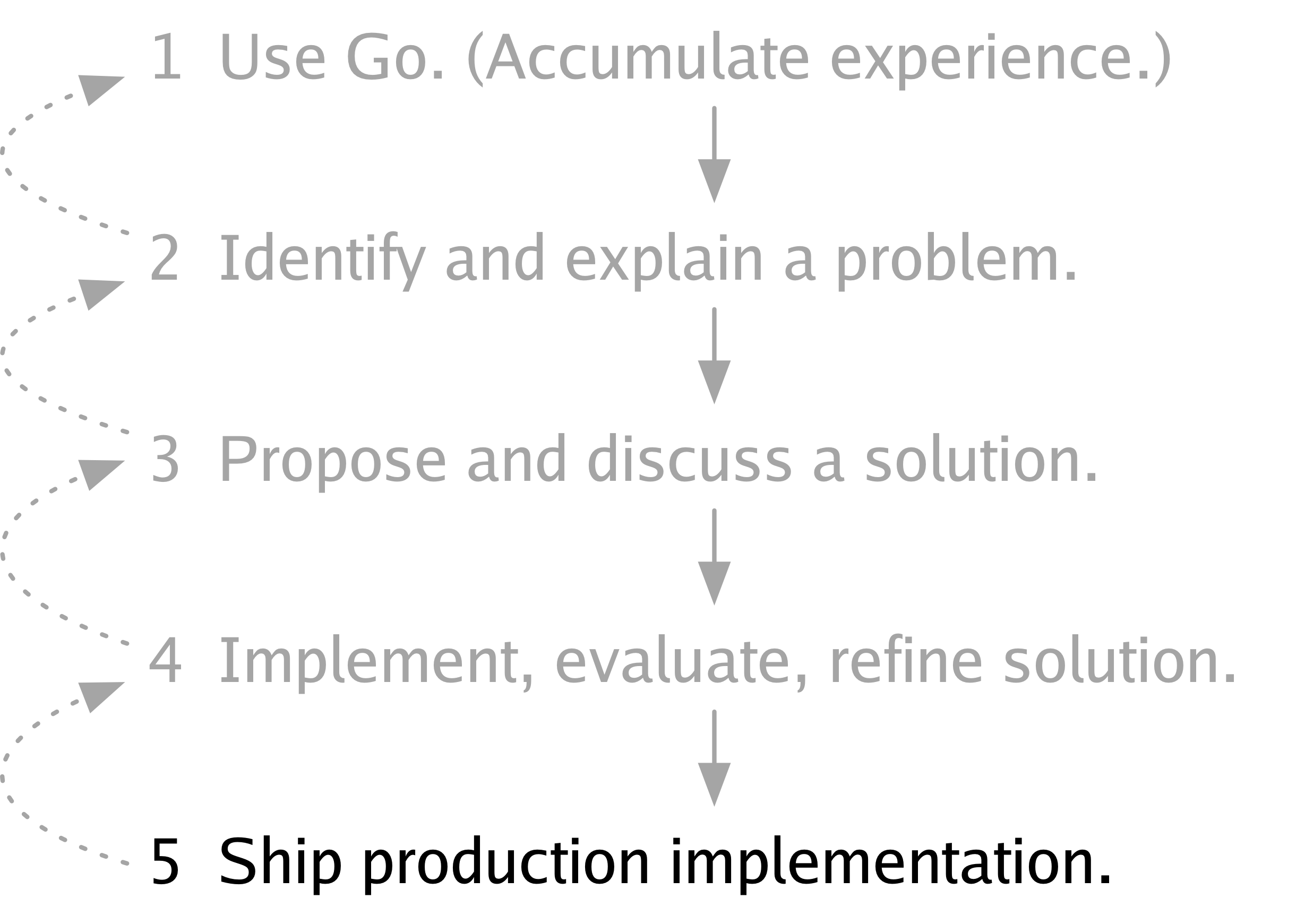
Part of the work since the open-source release of Go has been porting our informal process into the more formal world of mailing lists and issue trackers and half a million users, but I don’t think we’ve ever explicitly described our overall process. It’s possible we never consciously thought about it. Looking back, though, I think this is the basic outline of our work on Go, the process we’ve been following since the first prototype was running.
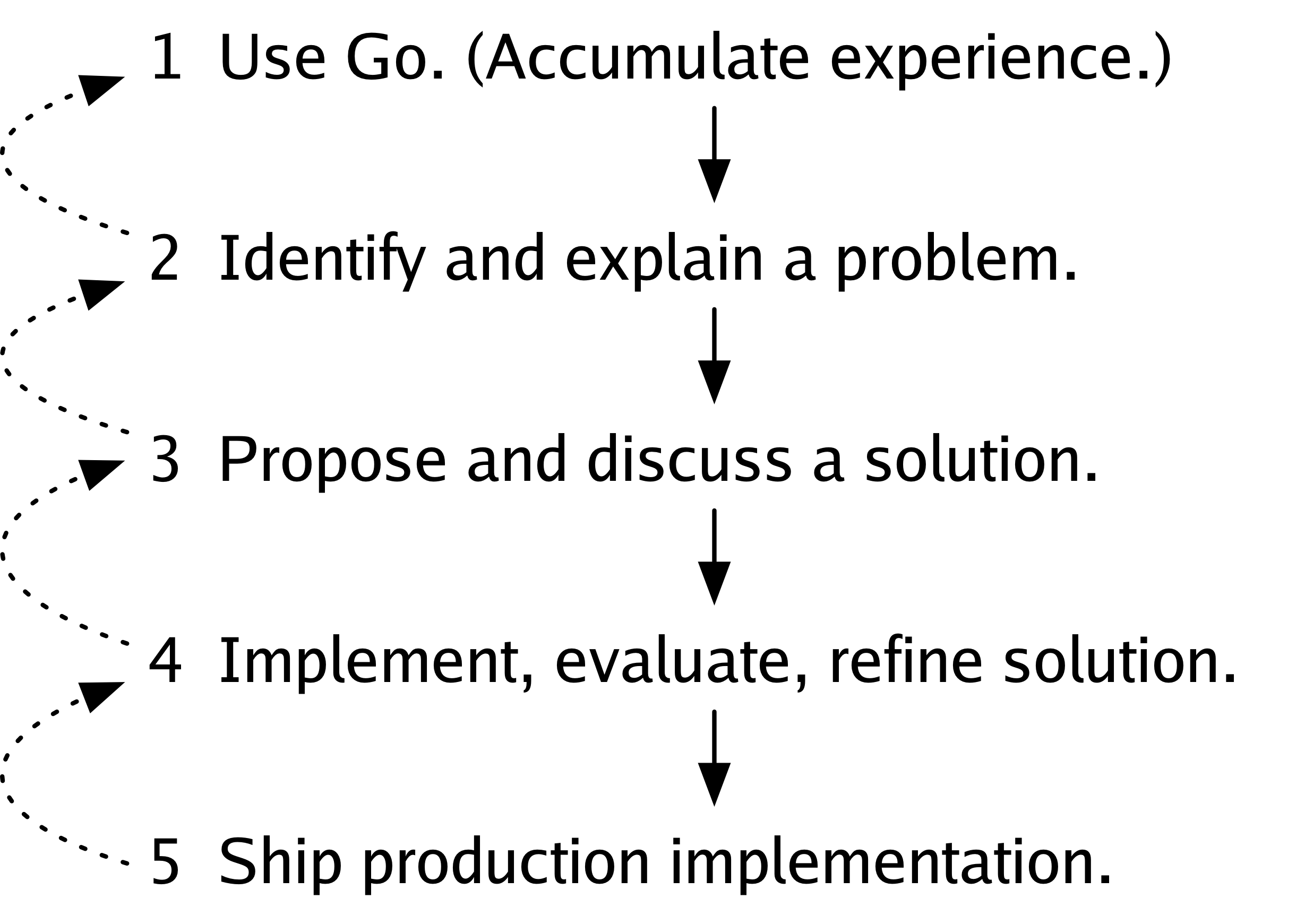
Step 1 is to use Go, to accumulate experience with it.
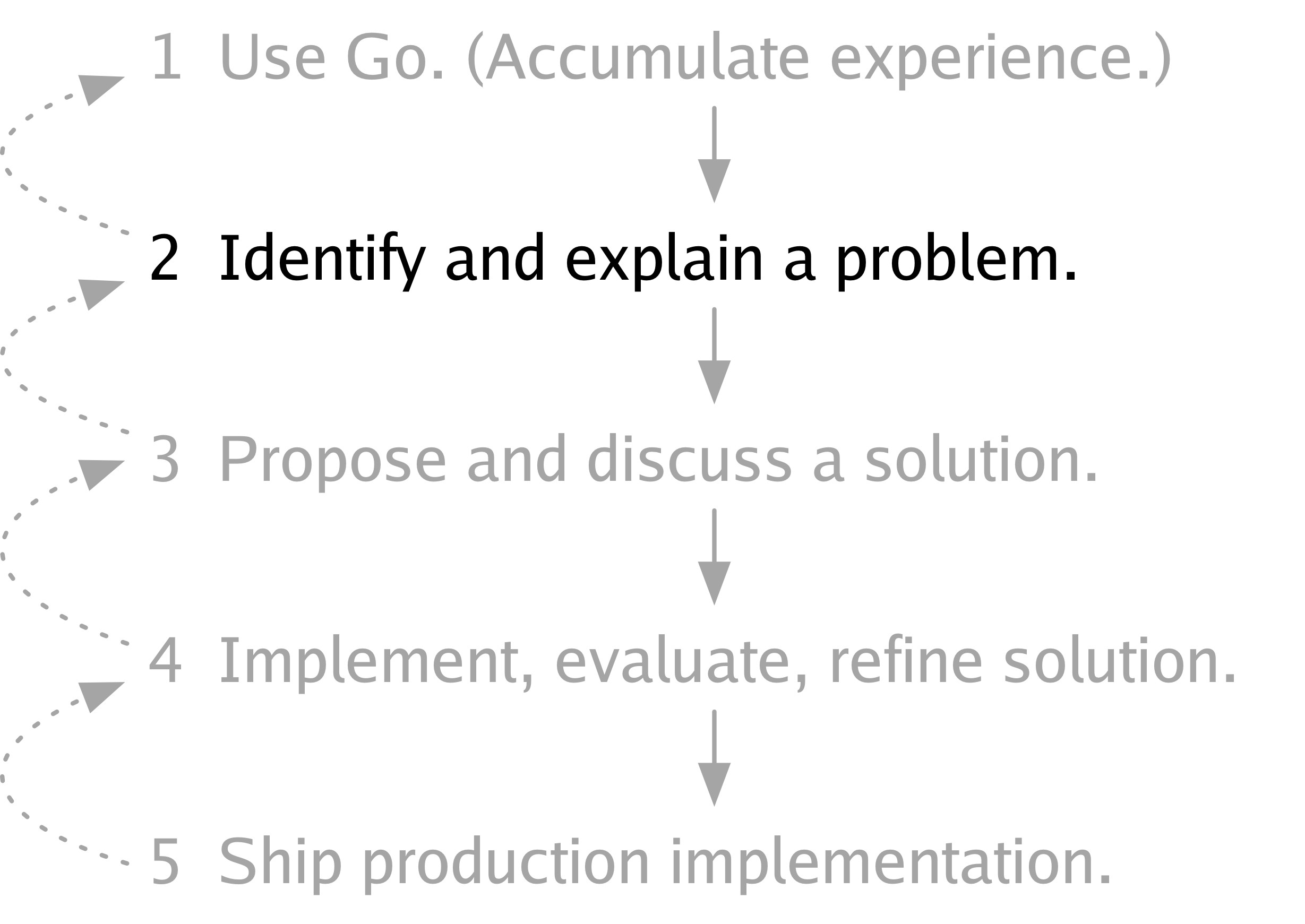
Step 2 is to identify a problem with Go that might need solving and to articulate it, to explain it to others, to write it down.
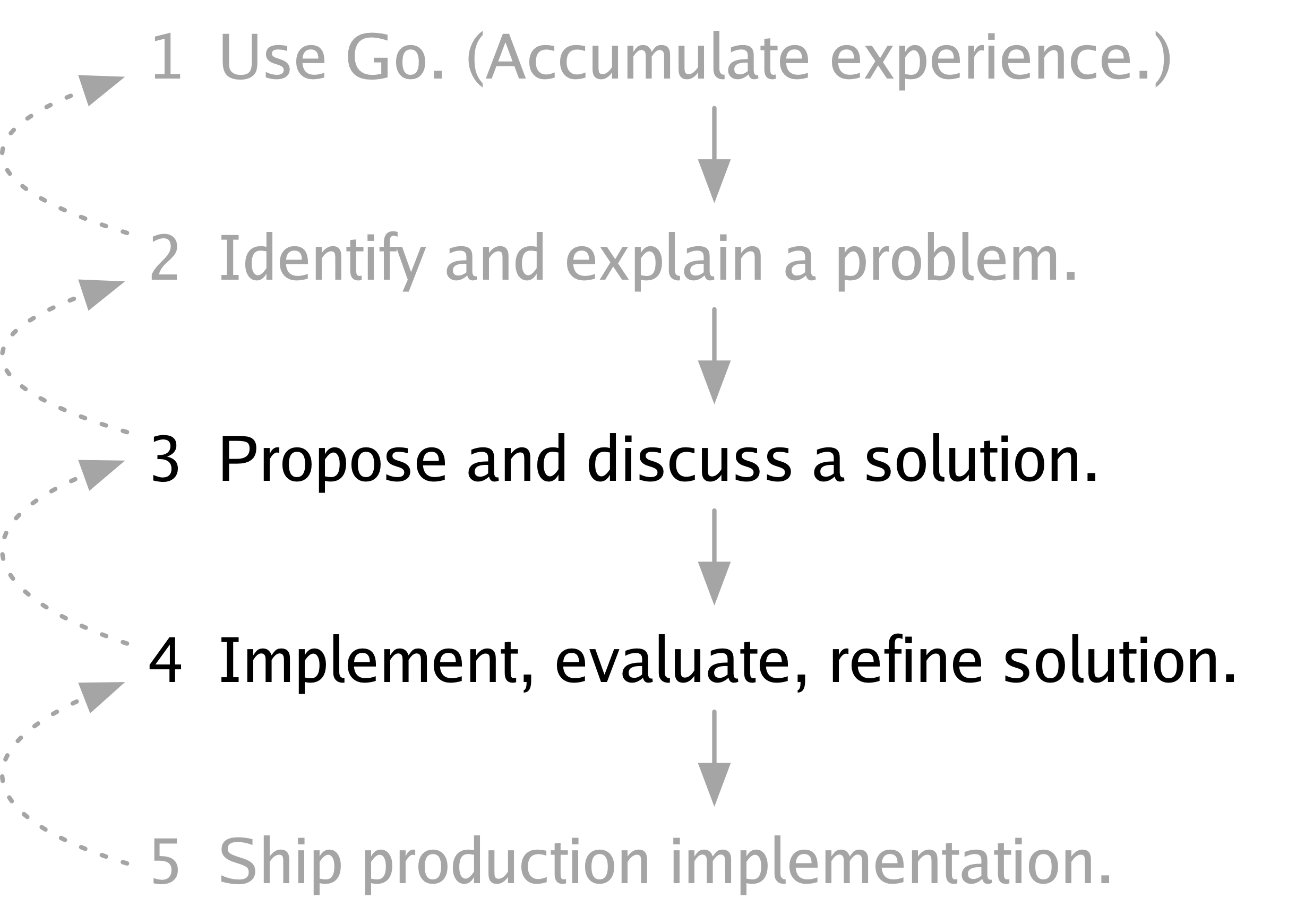
Step 3 is to propose a solution to that problem, discuss it with others, and revise the solution based on that discussion.
Step 4 is to implement the solution, evaluate it, and refine it based on that evaluation.
Finally, step 5 is to ship the solution, adding it to the language, or the library, or the set of tools that people use from day to day.
The same person does not have to do all these steps for a particular change. In fact, usually many people collaborate on any given step, and many solutions may be proposed for a single problem. Also, at any point we may realize we don’t want to go further with a particular idea and circle back to an earlier step.
Although I don’t believe we’ve ever talked about this process as a whole, we have explained parts of it. In 2012, when we released Go 1 and said that it was time now to use Go and stop changing it, we were explaining step 1. In 2015, when we introduced the Go change proposal process, we were explaining steps 3, 4, and 5. But we’ve never explained step 2 in detail, so I’d like to do that now.
(For more about the development of Go 1 and the shift away from language changes, see Rob Pike and Andrew Gerrand’s OSCON 2012 talk “The Path to Go 1.” For more about the proposal process, see Andrew Gerrand’s GopherCon 2015 talk “How Go was Made” and the proposal process documentation.)
Explaining Problems
There are two parts to explaining a problem. The first part—the easier part—is stating exactly what the problem is. We developers are decently good at this. After all, every test we write is a statement of a problem to be solved, in language so precise that even a computer can understand it. The second part—the harder part—is describing the significance of the problem well enough that everyone can understand why we should spend time solving it and maintaining a solution. In contrast to stating a problem precisely, we don’t need to describe a problem’s significance very often, and we’re not nearly as good at it. Computers never ask us “why is this test case important? Are you sure this is the problem you need to solve? Is solving this problem the most important thing you can be doing?” Maybe they will someday, but not today.
Let’s look at an old example from 2011. Here is what I wrote about renaming os.Error to error.Value while we were planning Go 1.

It begins with a precise, one-line statement of the problem: in very low-level libraries everything imports “os” for os.Error. Then there are five lines, which I’ve underlined here, devoted to describing the significance of the problem: the packages that “os” uses cannot themselves present errors in their APIs, and other packages depend on “os” for reasons having nothing to do with operating system services.
Do these five lines convince you that this problem is significant? It depends on how well you can fill in the context I’ve left out: being understood requires anticipating what others need to know. For my audience at the time—the ten other people on the Go team at Google who were reading that document—those fifty words were enough. To present the same problem to the audience at GothamGo last fall—an audience with much more varied backgrounds and areas of expertise—I needed to provide more context, and I used about two hundred words, along with real code examples and a diagram. It is a fact of today’s worldwide Go community that describing the significance of any problem requires adding context, especially illustrated by concrete examples, that you would leave out when talking to coworkers.
Convincing others that a problem is significant is an essential step. When a problem appears insignificant, almost every solution will seem too expensive. But for a significant problem, there are usually many solutions of reasonable cost. When we disagree about whether to adopt a particular solution, we’re often actually disagreeing about the significance of the problem being solved. This is so important that I want to look at two recent examples that show this clearly, at least in hindsight.
Example: Leap seconds
My first example is about time.
Suppose you want to time how long an event takes. You write down the start time, run the event, write down the end time, and then subtract the start time from the end time. If the event took ten milliseconds, the subtraction gives a result of ten milliseconds, perhaps plus or minus a small measurement error.
start := time.Now() // 3:04:05.000
event()
end := time.Now() // 3:04:05.010
elapsed := end.Sub(start) // 10 ms
This obvious procedure can fail during a leap second. When our clocks are not quite in sync with the daily rotation of the Earth, a leap second—officially 11:59pm and 60 seconds—is inserted just before midnight. Unlike leap years, leap seconds follow no predictable pattern, which makes them hard to fit into programs and APIs. Instead of trying to represent the occasional 61-second minute, operating systems typically implement a leap second by turning the clock back one second just before what would have been midnight, so that 11:59pm and 59 seconds happens twice. This clock reset makes time appear to move backward, so that our ten-millisecond event might be timed as taking negative 990 milliseconds.
start := time.Now() // 11:59:59.995
event()
end := time.Now() // 11:59:59.005 (really 11:59:60.005)
elapsed := end.Sub(start) // –990 ms
Because the time-of-day clock is inaccurate for timing events across clock resets like this, operating systems now provide a second clock, the monotonic clock, which has no absolute meaning but counts seconds and is never reset.
Except during the odd clock reset, the monotonic clock is no better than the time-of-day clock, and the time-of-day clock has the added benefit of being useful for telling time, so for simplicity Go 1’s time APIs expose only the time-of-day clock.
In October 2015, a bug report noted that Go programs could not time events correctly across clock resets, especially a typical leap second. The suggested fix was also the original issue title: “add a new API to access a monotonic clock source.” I argued that this problem was not significant enough to justify new API. A few months earlier, for the mid-2015 leap second, Akamai, Amazon, and Google had slowed their clocks a tiny amount for the entire day, absorbing the extra second without turning their clocks backward. It seemed like eventual widespread adoption of this “leap smear” approach would eliminate leap-second clock resets as a problem on production systems. In contrast, adding new API to Go would add new problems: we would have to explain the two kinds of clocks, educate users about when to use each, and convert many lines of existing code, all for an issue that rarely occurred and might plausibly go away on its own.
We did what we always do when there’s a problem without a clear solution: we waited. Waiting gives us more time to add experience and understanding of the problem and also more time to find a good solution. In this case, waiting added to our understanding of the significance of the problem, in the form of a thankfully minor outage at Cloudflare. Their Go code timed DNS requests during the end-of-2016 leap second as taking around negative 990 milliseconds, which caused simultaneous panics across their servers, breaking 0.2% of DNS queries at peak.
Cloudflare is exactly the kind of cloud system Go was intended for, and they had a production outage based on Go not being able to time events correctly. Then, and this is the key point, Cloudflare reported their experience in a blog post by John Graham-Cumming titled “How and why the leap second affected Cloudflare DNS.” By sharing concrete details of their experience with Go in production, John and Cloudflare helped us understand that the problem of accurate timing across leap second clock resets was too significant to leave unfixed. Two months after that article was published, we had designed and implemented a solution that will ship in Go 1.9 (and in fact we did it with no new API).
Example: Alias declarations
My second example is support for alias declarations in Go.
Over the past few years, Google has established a team focused on large-scale code changes, meaning API migration and bug fixes applied across our codebase of millions of source files and billions of lines of code written in C++, Go, Java, Python, and other languages. One thing I’ve learned from that team’s work is the importance, when changing an API from using one name to another, of being able to update client code in multiple steps, not all at once. To do this, it must be possible to write a declaration forwarding uses of the old name to the new name. C++ has #define, typedef, and using declarations to enable this forwarding, but Go has nothing. Of course, one of Go’s goals is to scale well to large codebases, and as the amount of Go code at Google grew, it became clear both that we needed some kind of forwarding mechanism and also that other projects and companies would run into this problem as their Go codebases grew.
In March 2016, I started talking with Robert Griesemer and Rob Pike about how Go might handle gradual codebase updates, and we arrived at alias declarations, which are exactly the needed forwarding mechanism. At this point, I felt very good about the way Go was evolving. We’d talked about aliases since the early days of Go—in fact, the first spec draft has an example using alias declarations—but each time we’d discussed aliases, and later type aliases, we had no clear use case for them, so we left them out. Now we were proposing to add aliases not because they were an elegant concept but because they solved a significant practical problem with Go meeting its goal of scalable software development. I hoped this would serve as a model for future changes to Go.
Later in the spring, Robert and Rob wrote a proposal, and Robert presented it in a Gophercon 2016 lightning talk. The next few months did not go smoothly, and they were definitely not a model for future changes to Go. One of the many lessons we learned was the importance of describing the significance of a problem.
A minute ago, I explained the problem to you, giving some background about how it can arise and why, but with no concrete examples that might help you evaluate whether the problem might affect you at some point. Last summer’s proposal and the lightning talk gave an abstract example, involving packages C, L, L1, and C1 through Cn, but no concrete examples that developers could relate to. As a result, most of the feedback from the community was based on the idea that aliases only solved a problem for Google, not for everyone else.
Just as we at Google did not at first understand the significance of handling leap second time resets correctly, we did not effectively convey to the broader Go community the significance of handling gradual code migration and repair during large-scale changes.
In the fall we started over. I gave a talk and wrote an article presenting the problem using multiple concrete examples drawn from open source codebases, showing how this problem arises everywhere, not just inside Google. Now that more people understood the problem and could see its significance, we had a productive discussion about what kind of solution would be best. The outcome is that type aliases will be included in Go 1.9 and will help Go scale to ever-larger codebases.
Experience reports
The lesson here is that it is difficult but essential to describe the significance of a problem in a way that someone working in a different environment can understand. To discuss major changes to Go as a community, we will need to pay particular attention to describing the significance of any problem we want to solve. The clearest way to do that is by showing how the problem affects real programs and real production systems, like in Cloudflare’s blog post and in my refactoring article.
Experience reports like these turn an abstract problem into a concrete one and help us understand its significance. They also serve as test cases: any proposed solution can be evaluated by examining its effect on the actual, real-world problems the reports describe.
For example, I’ve been examining generics recently, but I don’t have in my mind a clear picture of the detailed, concrete problems that Go users need generics to solve. As a result, I can’t answer a design question like whether to support generic methods, which is to say methods that are parameterized separately from the receiver. If we had a large set of real-world use cases, we could begin to answer a question like this by examining the significant ones.
As another example, I’ve seen proposals to extend the error interface in various ways, but I haven’t seen any experience reports showing how large Go programs attempt to understand and handle errors at all, much less showing how the current error interface hinders those attempts. These reports would help us all better understand the details and significance of the problem, which we must do before solving it.
I could go on. Every major potential change to Go should be motivated by one or more experience reports documenting how people use Go today and why that’s not working well enough. For the obvious major changes we might consider for Go, I’m not aware of many such reports, especially not reports illustrated with real-world examples.
These reports are the raw material for the Go 2 proposal process, and
we need all of you to write them, to help us understand your
experiences with Go. There are half a million of you, working in a
broad range of environments, and not that many of us.
Write a post on your own blog,
or write a Medium post,
or write a GitHub Gist (add a .md file extension for Markdown),
or write a Google doc,
or use any other publishing mechanism you like.
After you’ve posted, please add the post to our new wiki page,
golang.org/wiki/ExperienceReports.
Solutions
Now that we know how we’re going to identify and explain problems that need to be solved, I want to note briefly that not all problems are best solved by language changes, and that’s fine.
One problem we might want to solve is that computers can often compute
additional results during basic arithmetic operations, but Go does not
provide direct access to those results. In 2013, Robert proposed that
we might extend the idea of two-result (“comma-ok”) expressions to
basic arithmetic. For example, if x and y are, say, uint32 values,
lo, hi = x * y
would return not only the usual low 32 bits but also the high 32 bits
of the product. This problem didn’t seem particularly significant, so
we recorded the potential solution but didn’t implement it. We waited.
More recently, we designed for Go 1.9 a math/bits package that contains various bit manipulation functions:
package bits // import "math/bits"
func LeadingZeros32(x uint32) int
func Len32(x uint32) int
func OnesCount32(x uint32) int
func Reverse32(x uint32) uint32
func ReverseBytes32(x uint32) uint32
func RotateLeft32(x uint32, k int) uint32
func TrailingZeros32(x uint32) int
...
The package has good Go implementations of each function, but the compilers also substitute special hardware instructions when available. Based on this experience with math/bits, both Robert and I now believe that making the additional arithmetic results available by changing the language is unwise, and that instead we should define appropriate functions in a package like math/bits. Here the best solution is a library change, not a language change.
A different problem we might have wanted to solve, after Go 1.0, was the fact that goroutines and shared memory make it too easy to introduce races into Go programs, causing crashes and other misbehavior in production. The language-based solution would have been to find some way to disallow data races, to make it impossible to write or at least to compile a program with a data race. How to fit that into a language like Go is still an open question in the programming language world. Instead we added a tool to the main distribution and made it trivial to use: that tool, the race detector, has become an indispensable part of the Go experience. Here the best solution was a runtime and tooling change, not a language change.
There will be language changes as well, of course, but not all problems are best solved in the language.
Shipping Go 2
Finally, how will we ship and deliver Go 2?
I think the best plan would be to ship the backwards-compatible parts of Go 2 incrementally, feature by feature, as part of the Go 1 release sequence. This has a few important properties. First, it keeps the Go 1 releases on the usual schedule, to continue the timely bug fixes and improvements that users now depend on. Second, it avoids splitting development effort between Go 1 and Go 2. Third, it avoids divergence between Go 1 and Go 2, to ease everyone’s eventual migration. Fourth, it allows us to focus on and deliver one change at a time, which should help maintain quality. Fifth, it will encourage us to design features to be backwards-compatible.
We will need time to discuss and plan before any changes start landing in Go 1 releases, but it seems plausible to me that we might start seeing minor changes about a year from now, for Go 1.12 or so. That also gives us time to land package management support first.
Once all the backwards-compatible work is done, say in Go 1.20, then we can make the backwards-incompatible changes in Go 2.0. If there turn out to be no backwards-incompatible changes, maybe we just declare that Go 1.20 is Go 2.0. Either way, at that point we will transition from working on the Go 1.X release sequence to working on the Go 2.X sequence, perhaps with an extended support window for the final Go 1.X release.
This is all a bit speculative, and the specific release numbers I just mentioned are placeholders for ballpark estimates, but I want to make clear that we’re not abandoning Go 1, and that in fact we will bring Go 1 along to the greatest extent possible.
Help Wanted
We need your help.
The conversation for Go 2 starts today, and it’s one that will happen in the open, in public forums like the mailing list and the issue tracker. Please help us at every step along the way.
Today, what we need most is experience reports. Please tell us how Go is working for you, and more importantly not working for you. Write a blog post, include real examples, concrete detail, and real experience. And link it on our wiki page. That’s how we’ll start talking about what we, the Go community, might want to change about Go.
Thank you.
Next article: Contributors Summit
Previous article: Introducing the Developer Experience Working Group
Blog Index